实现一个简单的MVVM-1
记录一下对对象实现一个简单的mvvm的过程,这部分主要是最基本的构造。
Vue的MVVM响应式原理 在之前的文章中我们知道Vue的MVVM的核心是数据劫持(数据代理)、数据编译和”发布订阅模式”。
在我们创建一个Vue实例时,其实Vue做了这些事情:
创建了入口函数,分别new了一个数据观察者Observer和一个指令解析器Compile;
Compile解析所有DOM节点上的Vue指令,提交到更新器Updater(实际上是一个对象);
Updater把数据(如{{}}, msg, @click)替换,完成页面初始化渲染;
Observer使用Object.defineProperty劫持数据,其中的getter和setter通知变化给依赖器Dep;
Dep中加入观察者Watcher,当数据发生变化时,通知Watcher更新;
Watcher取到旧值和新值,在回调函数中通知Updater更新视图;
Compile中每个指令都new了一个Watcher,用于触发Watcher的回调函数进行更新。
我们按照这个思路来实现一个简单的vue3-mvvm,目标是可以编译类似如下的html文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <body > <div id ="app" > <p > Count is: {{ count }}</p > <input type ="text" v-model ="message" > <h1 > {{ message }}</h1 > <p c-if ="count >= 3" > </p > <p :style ="{color: red}" > </p > <button c-on:click ="handleClick" > click</button > <button @click ="handleClick" > @click2</button > </div > </body >
js部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 let app = createApp ({data (return {foo : "bar" ,count : 0 computed : {com (return ("I'm computed of reversed foo: " + this .foo .split ("" ).reverse ().join ("" )methods : {countAdd (this .count ++;mount ("#app" );
分析 我们知道,vue3用createApp来创建一个应用实例,然后用.mount()来挂载一个应用。每一个应用所有的data均挂载在View
Model上,现在我们来构建cainVM。对于一个VM,我们需要存储挂载的元素和HTML模板(如果有的话)、状态选项和编译后的VM。对于VmOptions,参考Vue我们需要实现data, setup等状态选项。
1 2 3 4 5 6 7 8 9 10 11 12 13 class cApp implements cainVm {$template : string $el : HTMLElement $options : cainVmOptions$data : object $compile : VmCompiler mount (el?: string | HTMLElement )
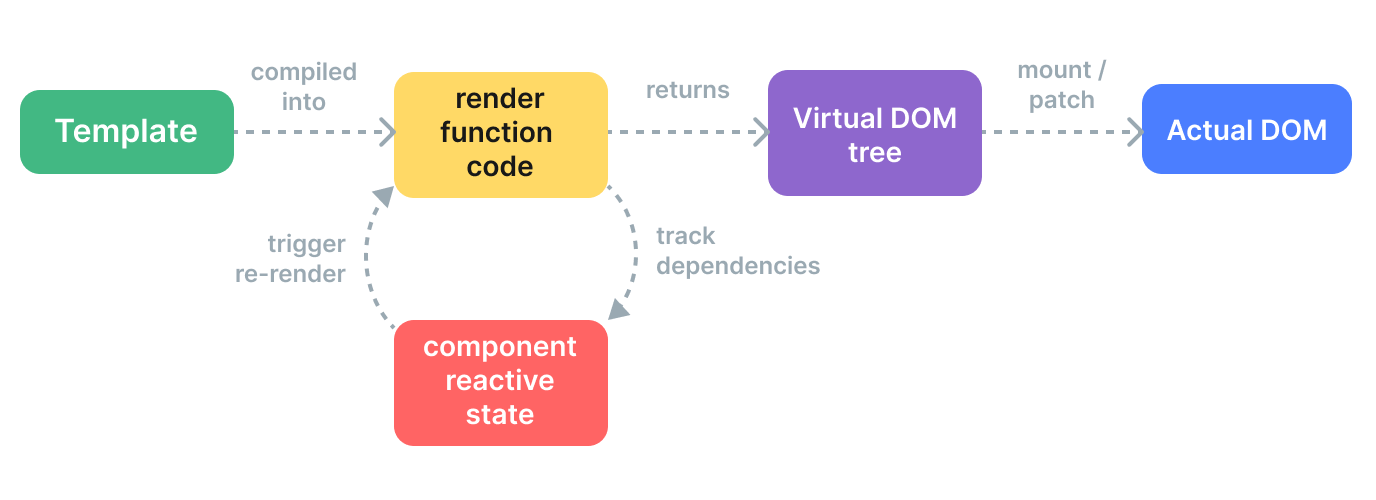
在挂载时,会发生编译、挂载、更新三件事。获得挂载信息后传入compiler,compiler对其进行解析,模板被编译为渲染函数 ,用来返回虚拟
DOM 树。渲染器的作用是把虚拟 DOM 渲染为真实
DOM。由于在响应式视图中,可能会存在大量的需要随时更新的DOM,如果每次数据更新都全部重新渲染,会造成大量的性能开销(真实DOM的操作耗时远远大于执行Javascript
语句),因此我们采虚拟DOM+真实DOM来进行DOM渲染。
render pipeline
为了能重新运行计算的代码来更新,我们需要将计算包装为一个
update() 函数,这个 update()
函数会产生一个副作用 ,或者就简称为作用
(effect),因为它会更改程序里的状态。例如:
1 2 3 4 5 let A2 function update (A2 = A0 + A1
A0 和 A1
被视为这个作用的依赖
(dependency),因为它们的值被用来执行这个作用。因此这次作用也可以被称作它的依赖的一个订阅者
(subscriber)。例如由于 A0 和 A1 在
update() 执行时被访问到了,则 update()
需要在第一次调用之后成为 A0 和 A1
的订阅者。当检测到变量变化时,应该通知其所有订阅了的副作用重新执行。我们需要一个函数,能够在
A0 或 A1 (这两个依赖 )
变化时调用 update() (产生作用 )。
当一个依赖发生变化后,副作用会重新运行,这时候会创建一个更新后的虚拟
DOM
树。运行时渲染器遍历这棵新树,将它与旧树进行比较,然后将必要的更新应用到真实
DOM 上去。
我们实现一个MVVM主要有三个部分:编译器、渲染器、响应式系统。
响应式系统 数据劫持 在Vue3,我们使用Proxy来实现数据劫持。与Vue2使用的Object.defineProperty的区别在于Object.defineProperty必须对于确定的key值进行响应式的定义,而Proxy在定义的时候并不用关心key值,只要你定义了get方法,那么后续对于data上任何属性的访问(哪怕是不存在的),都会触发get的劫持,set也是同理。下面的代码是Vue3官方文档给出的伪代码,我们根据这个来分析如何实现响应式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 function reactive (obj ) {return new Proxy (obj, {get (target, key ) {track (target, key)return target[key]set (target, key, value ) {trigger (target, key)function ref (value ) {const refObject = {get value () {track (refObject, 'value' )return valueset value (newValue ) {trigger (refObject, 'value' )return refObject
由于Proxy实现的reactive只能劫持对象,Vue对于非对象数据采用包装到具有value属性的对象,并代理这个包装对象实现劫持,这就是ref的由来。
在运行前我们需要设置一个副作用activeEffect,供后续处理。在
track()
内部,我们会检查当前是否有正在运行的副作用。如果有,我们会查找到一个存储了所有追踪了该属性的订阅者的
Set,然后将当前这个副作用作为新订阅者添加到该 Set 中。在
trigger()
之中,我们会再查找到该属性的所有订阅副作用。但这一次我们需要执行它们。副作用订阅将被存储在一个全局的
WeakMap<target, Map<key, Set<effect>>>
数据结构中。如果在第一次追踪时没有找到对相应属性订阅的副作用集合,会在这里新建一个集合。
下面是一个简单的响应式实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const effectBucket = new Set ()const data = { text : "hello" }const RefObj = new Proxy (data, {get (target, key ) {add (effect)return target[key]set (target, key, newVal : any ) {forEach (fn =>fn ())return true
从上面我们可以看出,一个响应系统的工作流程大致如下:
当读取操作发生时,将副作用函数收集到“桶”中;
当设置操作发生时,从“桶”中取出副作用函数并执行。
我们需要一个注册副作用函数的机制,正是前文提到的activeEffect。同时我们也需要注意,如果响应式数据上设置了一个不存在的属性,且副作用函数中并没有读取该属性的值,理论上不会触发副作用函数的重新执行,但实际上恰恰相反。这是因为没有在副作用函数与被操作的目标字段之间建立明确的联系。提到建立联系,我们很容易想到Map数据类型。我们使用WeakMap代替Set来解决这个问题。
不难发现,代理对象、字段名和副作用函数之间存在着树形结构:
同样的,它们的数据结构也存在对应的类似结构:
我们把Set数据结构所存储的副作用函数集合称为key的依赖集合。使用WeakMap的原因是它对key是弱引用,当target没有任何引用时,垃圾回收器会完成回收任务,如果使用Map,即使用户代码对target没有任何引用,也不会被回收,可能会导致内存溢出。
收集副作用函数逻辑track:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 export function track (target : any , key : string | symbol if (!activeEffect) return target[key]let depsMap = effectBucket.get (target)if (!depsMap) {set (target, (depsMap = new Map ()))let deps = depsMap.get (key)if (!deps) {set (key, (deps = new Set ()))add (activeEffect)
触发副作用函数重新执行的逻辑封装函数trigger:
1 2 3 4 5 6 function trigger (target : any , key : string | symbol const depsMap = bucket.get (target)if (!depsMap) { return false }const effects = depsMap.get (key)forEach ((fn : Function fn ())
响应式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 let activeEffect : Function const effectBucket = new WeakMap ()const refObj = new Proxy (data, {get (target, key ) {track (target, key)return target[key]set (target, key, newVal ) {trigger (target, key)function effect (fn ) {fn ()
处理不必要的更新 当某一变量发生变化时,代码执行的分支会跟着跟着变化,称为分支切换,典型的例子就是三目运算符a ? b : c。当发生分支切换时,可能会产生遗留的副作用函数,运行时可能会触发不必要的更新。解决方法就是每次副作用函数执行时,先从所有含有它的依赖集合中删除该副作用函数,再重新建立联系,这样在新的联系中就不会包含遗留(不需要)的副作用函数。
我们设置一个EffectFunction,在Function的基础上新增deps属性,该属性是一个数组,用来存储所有包含当前副作用函数的依赖集合:
1 2 3 4 5 6 7 8 9 10 function effect (fn ) {const effectFn : EffectFunction = () => {fn ()deps = []effectFn ()
track函数用于收集副作用函数,我们会发现其中的deps就是我们要的依赖集合,所以很适合在track中收集effectFn.deps:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 export function track (target : any , key : string | symbol if (!activeEffect) return target[key]let depsMap = effectBucket.get (target) as DepsMap if (!depsMap) {set (target, (depsMap = new Map ()))let deps = depsMap.get (key)if (!deps) {set (key, (deps = new Set ()))add (activeEffect)deps .push (deps)
有了effectFn.deps后,我们就可以根据它来获取所有相关联的依赖集合,进而移除不需要的副作用函数:
1 2 3 4 5 6 7 8 9 10 11 function effect (fn ) {const effectFn : EffectFunction = () => {cleanup (effectFn) fn ()deps = []effectFn ()
cleanup函数的简单实现:
1 2 3 4 5 6 7 8 function cleanup (effectFn ) {if (effectFn.deps ) {for (let deps of effectFn.deps ) {delete (effectFn)deps = []
目前有个问题,如果我们目前的副作用函数是被需要的,那么在trigger函数的effects && effects.forEach((fn) => fn())中,我们先删除了该函数再添加了该函数,在集合中该值被删除但被重新添加,如果此时调用forEach遍历集合并没有结束,则会重新访问再次添加的值,引发死循环。解决方法也很简单,我们只需构造另外一个集合并遍历即可,此时我们再次添加该函数的集合就不是我们遍历的集合了:
1 2 3 4 5 6 7 8 export function trigger (target : any , key : string | symbol const depsMap = effectBucket.get (target)if (!depsMap) { return false }const effects = depsMap.get (key)const effectsToRun = new Set (effects)forEach ((fn ) => fn ())
effect嵌套与effect栈 当副作用函数之间发生嵌套时,我们现有的响应式系统会出现一些问题。例如当EffectFn1中嵌套EffectFn2时:
1 2 3 4 5 6 7 8 9 10 11 12 effect (function Fn1 (console .log ("Fn1" )foo effect (function Fn2 (console .log ("Fn2" )bar setTimeout (() => {foo = "asd"
我们会发现输出了三次,分别是Fn1, Fn2, Fn2,前面两次是初始化时的正常输出,而第三次则是因为activeEffect存储的是EffectFn2,且永远不会恢复。如果存在effect嵌套,我们目前的系统全局activeEffect永远是初始化时最后执行的那个副作用函数。
为了解决这个问题,我们需要一个副作用函数栈effectStack,副作用函数执行时压栈,执行完毕后退栈,并始终让activeEffect指向栈顶:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 function effect (fn ) {const effectFn : EffectFunction = () => {cleanup (effectFn) push (activeEffect)fn ()pop ()length - 1 ]deps = []effectFn ()
避免无限递归循环 我们有这么一个副作用函数:
1 effect (() => { refObj.foo = refObj.foo + 1 })
在这个语句中,首先读取obj.foo的值,这会触发track操作,将当前副作用函数收集到“桶”中,接着将其加1后再赋值给obi.foo,此时会触发
trigger
操作,即把“桶”中的副作用函数取出并执行。但问题是该副作用函数正在执行中,还没有执行完毕,就要开始下一次的执行。这样会导致无限递归地调用自己,于是就产生了栈溢出。
我们为trigger添加护卫条件,如果trigger触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 function trigger (target : any , key : string | symbol const depsMap = effectBucket.get (target)if (!depsMap) { return false }const effects = depsMap.get (key)const effectsToRun = new Set (effects)forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)forEach ((effectFn ) => effectFn ())
调度执行 可调度性事响应系统非常重要的特性,当trigger触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式。我们为EffectFunction添加选项参数options,允许用户指定调度器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 function effect (fn, options ) {const effectFn : EffectFunction = () => {cleanup (effectFn) push (activeEffect)fn ()pop ()length - 1 ]options = optionsdeps = []effectFn ()
我们在trigger函数中触发副作用函数重新执行时就可以直接调用用户传递的调度器函数,从而把控制权交给用户:
1 2 3 4 5 6 7 8 effectsToRun.forEach ((effectFn ) => {const EffectFunctionOptions = effectFn.options as EffectOptions if (EffectFunctionOptions .scheduler ) {EffectFunctionOptions .scheduler (effectFn)else {effectFn ()
我们可以使用调度器来实现多次修改响应式数据只触发一次更新。
computed和lazy我们在EffectOptions中添加懒加载布尔值lazy,用于不希望函数立即执行,而在需要的场景执行的情况。接下来修改effect函数,仅当lazy属性为false时才执行该函数,返回effectFn,用于在需要的时候调用。我们把传递给effect的函数看作一个getter,那么我们在手动执行副作用函数时,就可以拿到返回值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 function effect (fn, options ) {const effectFn : EffectFunction = () => {cleanup (effectFn) push (activeEffect)const res = fn ()pop ()length - 1 ]return resoptions = optionsdeps = []if (!options.lazy ) effectFn ()return effectFn
不难看出传递给effect的函数fn才是真正的副作用函数,effectFn的返回值就是副作用函数的执行结果。实现了懒执行,我们就可以开始实现计算属性了。除了懒执行外,我们还需要缓存计算的结果,而不是读取时才会进行计算。如果在读取时才进行计算并得到值,多次访问时会导致effectFn多次计算,而值本身并没有发生变化。
当完成一次计算时,dirty的值始终为false,这会导致再次计算时访问到的值不变,我们用之前的scheduler来解决这个问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 export function computed (getter ) {let cachelet dirty = true const effectFn = watchEffect (getter, {lazy : true ,scheduler (true const obj : { readonly value : any } = {get value () {if (dirty) {effectFn ()false return this .value return obj
当我们修改obj.foo时,我们希望副作用函数会重新执行,但事实上目前的代码并不会。
1 2 3 4 5 6 7 const sum = computed (() => obj.foo + obj.bar )effect (() => {console .log (sum.value )foo ++
不难看出当另一个effect读取计算属性的值时,这本质上是一个effect嵌套。对于计算属性的getter函数来说,它内部的响应式数据只会把computed内部的effect收集为依赖,而当把计算属性用于另外一个effect时,就会发生effect嵌套,外层的effect不会被内层的effect中的响应式数据收集。解决方法也很简单,当读取计算属性值时,手动调用track函数;当计算属性依赖的响应式数据发生变化时,手动调用trigger函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 export function computed (getter ) {let cachelet dirty = true const effectFn = watchEffect (getter, {lazy : true ,scheduler (if (!dirty) { true trigger (obj, "value" )const obj : { readonly value : any } = {get value () {if (dirty) {effectFn ()false track (obj, "value" )return cachereturn obj
watchwatch
本质是观测一个响应式数据,当数据发生变化时通知并执行相应的回调函数。watch的实现本质就是利用了effect以及scheduler选项,当响应式数据发生变化时,触发scheduler调度函数执行,相当于一个回调函数。我们需要一个traverse函数进行递归读取操作,watch函数允许观测响应式数据和getter函数,同时能通过lazy在回调函数中获取旧值和新值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 function watch<T>(target : T | (() => T) | Ref <T>, callback) {let getterif (typeof target = "function" ) getter = targetelse getter = () => traverse (target)let newVal, oldValconst effectFn = effect (() => getter (), {lazy : true ,scheduler (effectFn ()callback (newVal, oldVal)effectFn ()function traverse (value, traversed = new Set () ) {if (typeof value !== 'object' || value === nul || traversed.have (value)) { return }add (value)for (const key in value) {traverse (value[key], traversed)
默认情况下,watch的回调只会在响应式数据发生变化时才执行,如果需要立即执行,我们可以设置一个可选参数immediate来控制。如果还需要指定回调函数的其他执行时机,可以使用flush选项来指定,类型为post | pre | sync,在这里不做过多叙述。
我们还需要一个让副作用过期的手段。在开发过程中对于异步编程我们可能会遇到旧值覆盖新值的问题,我们为watch的回调函数添加第三个参数onInvalidate来注册一个回调,这个回调函数会在当前副作用函数过期时执行,当在watch内部检测到变更时,在副作用函数重新执行之前会先调用我们通过onInvalidate注册的过期回调。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 export function watch<T>(target : T | (() => T) | Ref <T>, callback : WatchCallbackFn <T>, options : WatchOptions = {}) {let getter : Function if (typeof target === 'function' ) {else {() => traverse (target)let oldVal : T, newVal : Tlet expiredEffects : EffectFunction const onInvalidate = (fn : EffectFunction const schedule = (if (expiredEffects) {expiredEffects ()effectFn ()callback (newVal, oldVal, onInvalidate)const effectFn = effect (() => getter (), {lazy : true ,scheduler : () => {if (options.flush === 'post' ) {const p = Promise .resolve ()then (schedule)else {schedule ()if (options.immediate ) {schedule ()else {effectFn ()
我们可以设置一个标志expired来标识当前副作用函数的执行是否过期。如果我们修改了两次target的值,第一次修改是立即执行的,由于我们在回调函数内调用了onInvalidate,所以会注册一个过期回调(注意,这里只是注册并不会运行),当第二次修改时就会执行回调函数。这时要注意的是,在我们的实现中,每次执行回调函数之前先检查过期回调是否存在,如果存在,会优先执行过期回调。由于在
watch
的回调函数第一次执行的时候,我们已经注册了一个过期回调,所以在watch
的回调函数第二次执行之前,会优先执行之前注册的过期回调,这会使得第一次执行的副作用函数内闭包的变量expired的值变为
true,即副作用函数的执行过期了。
watchEffect在上文中我们知道需要这么一个函数,能够在依赖变化时调用
update() 产生作用,这就是Vue
提供的用于创建响应式副作用的函数watchEffect()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 export function watchEffect (fn : EffectFunction , options : EffectOptions EffectFunction {const effectFn : EffectFunction = () => {cleanup (effectFn)push (activeEffect)const res = fn ()pop ()length - 1 ]return resoptions = optionsdeps = []if (!options.lazy ) {effectFn ()return effectFn
很眼熟吧,其实就是上文中一直用到的effect函数。
总结一下 一个响应式数据最基本的实现依赖于对“读取”和“设置”操作的拦截。当“读取”操作发生时,我们将当前执行的副作用函数存储到“桶”中;当
“设置”操作发生时,再将副作用函数从“桶”里取出并执行。而后我们使用WeakMap配合Map构建了新的“桶”结构,从而能够在响应式数据与副作用函数之间建立更加精确的联系。
我们还讨论了分支切换导致的冗余副作用的问题,这个问题会导致副作用函数进行不必要的更新。为了解决这个问题,我们需要在每次副作用函数重新执行之前,清除上一次建立的响应联系,而当副作用函数重新执行后,会再次建立新的响应联系,新的响应联系中不存在冗余副作用问题,从而解决了问题。
为了避免在响应式数据与副作用函数之间建立的响应联系发生错乱,我们需要使用副作用函数栈来存储不同的副作用函数。当一个副作用函数执行完毕后,将其从栈中弹出。如果trigger触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行。
所谓可调度,指的是当trigger动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式。为了实现调度能力,我们为effect函数增加了第二个选项参数,可以通过scheduler选项指定调用器,这样用户可以通过调度器自行完成任务的调度。
计算属性实际上是一个懒执行的副作用函数,我们通过lazy选项使得副作用函数可以懒执行。被标记为懒执行的副作用函数可以通过手动方式让其执行。
watch
的实现原理本质上利用了副作用函数重新执行时的可调度性。一个watch本身会创建一个
effect,当这个effect依赖的响应式数据发生变化时,会执行该effect的调度器函数,即scheduler,可以理解为一个回调函数。
过期的副作用函数会导致竞态问题。为了解决这个问题,我们可以为watch的回调函数设计了第三个参数,即onInvalidate。它是一个函数,用来注册过期回调。每当watch的回调函数执行之前,会优先执行用户通过onInvalidate注册的过期回调。
响应式系统实现 在这之前我们知道Vue3响应式数据是基于Proxy实现的,我们再次了解一下Proxy和与之相关联的Reflect。Proxy可以创建一个代理对象,能够实现对其他对象基本语义 的代理,注意只能代理对象,无法代理非对象值,它允许我们拦截并重新定义对一个对象的基本操作。我们使用get拦截读取操作,set拦截设置操作,apply拦截函数调用。
Reflect 是一个内建对象,可简化 Proxy
的创建。对于任意 Proxy 捕捉器,都有一个带有相同参数的
Reflect
调用。我们可以使用它们将调用转发给目标对象,也可以将操作转发给原始对象。Reflect.get函数还能接收第三个参数,即指定接收者receiver,你可以把它理解为函数调用过程中的this。
我们回到之前的响应式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const data = { text : "hello" }const refObj = new Proxy (data, {get (target, key ) {track (target, key)return target[key]set (target, key, newVal ) {trigger (target, key)function effect (fn ) {fn ()
如果我们给data加上get属性:
1 2 3 4 5 6 7 8 9 10 const data = { text : "hello" ,get bar () {return this .data watchEffect (() => {console .log (refObj.bar )
此时我们进行数据劫持后再修改refObj.text的数据,会发现并没有触发响应。问题就出在
bar
属性的访问器函数getter里,我们读取时在get拦截函数通过
target[key]返回属性值,而我们的target是原始数据data,说明我们最后访问的其实是obj.text。在副作用函数内通过原始对象访问它的某个属性是不会建立响应联系的。
解决办法就是使用Reflect.get的第三个参数receiver,代表谁在读取属性(有些情况需要使用.bind(obj))。
1 2 3 4 get (target, key, receiver ) {track (target, key)return Reflect .get (target, key, receiver)
当我们使用代理对象refObj访问 bar
属性时,那么receiver就是refObj,此时访问器属性bar的this指向的就是refObj。
在响应系统中读取是一个很宽泛的概念,我们需要拦截一切读取操作,以便数据变化时能够正确触发响应:
访问属性:obj.foo
判断对象或原型上是否存在给定的key:key in obj
使用for ... in循环遍历对象
对于访问属性,只需根据已经给出的代码就可以拦截。
对于in操作符,在ES规范中提到其返回的是? HasProperty(rval, ? ToPropertyKey(lval)),可以发现,in
操作符的运算结果是通过调用一个叫作HasProperty的抽象方法得到的。它对应的拦截函数名叫
has,因此我们可以通过 has 拦截函数实现对 in 操作符的代理:
1 2 3 4 has (target, key ) {track (target, key)return Reflect .has (target, key)
对于for ... in循环,执行规则中有一子步骤让 iterator
的值为? EnumerateObjectProperties(obj) ,关键点在于
EnumerateObjectProperties(obj),这里的EnumerateObjectProperties是一个抽象方法,该方法返回
一个迭代器对象。该方法是一个 generator 函数,接收一个参数obj,obj
就是被for...in循环遍历的对象,其关键点在于使用Reflect.ownKeys(obj)来获取只属于对象自身拥有的键。我们可以使用ownKeys拦截函数来拦截Reflect.ownKeys操作。
我们在使用track函数进行追踪的时候,将ITERATE_KEY作为追踪的
key,因为ownKeys拦截函数与 get/set 拦截函数不同,在 set/get
中,我们可以得到具体操作的
key,但是在ownKeys中,我们只能拿到目标对象 target。
1 2 3 4 5 6 7 const ITERATE_KEY = Symbol ()ownKeys (target ) {track (target, ITERATE_KEY )return Reflect .onwKeys (target)
既然追踪的是
ITERATE_KEY,那么相应地,在触发响应的时候也应该触发它才行。当我们为obj添加新的属性时,并不会触发副作用函数重新执行。添加新属性时触发set拦截函数执行,此时接收到的key就是字符串bar,因此调用trigger时只触发了与bar相关的副作用函数重新执行,但for .. in循环是在副作用函数与ITERATE_KEY之间建立联系,与bar一点关系没有。我们只需要将于ITERATE_KEY相关联的副作用函数也取出来执行即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 function trigger (target : any , key : string | symbol const depsMap = effectBucket.get (target)if (!depsMap) { return false }const effects = depsMap.get (key)const iterateEffects = depsMap.get (ITERATE_KEY )const effectsToRun = new Set (effects)forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)forEach ((effectFn ) => {const EffectFunctionOptions = effectFn.options as EffectOptions if (EffectFunctionOptions .scheduler ) {EffectFunctionOptions .scheduler (effectFn)else {effectFn ()
接下来是删除属性,delete
操作符的行为依赖[[Delete]]内部方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 deleteProperty (target, key ) {const hadKey = Object .prototype hasOwnProperty .call (target, key)const res = Reflect .deleteProperty (target, key)if (res && hadKey) {trigger (target, key, "DELETE" )return res
无论是添加或删除新属性,还是修改已有的属性值,其基本语义都是[[Set]],我们都是通过
set
拦截函数来实现拦截的,设置属性操作发生时,就需要我们在set拦截函数内能够区分操作的类型。如以下代码所示:
1 2 3 4 5 6 7 8 9 10 11 12 const refObj = new Proxy (data, {set (target, key, newVal, receiver ) {const type = Object .prototype hasOwnProperty .call (target, key) ? 'SET' : 'ADD' const res = Reflect .set (target, key, newVal, receiver)trigger (target, key, type )return res
由于删除操作会使得对象的键变少,它会影响for...in循环的次数,因此当操作类型为
‘DELETE’ 时,我们也应该触发那些与 ITERATE_KEY
相关联的副作用函数重新执行。在trigger中通过type区分当前操作类型,并且只有当操作类型type为
‘ADD’ 和 ‘DELETE’
时,才会触发与ITERATE_KEY相关联的副作用函数重新执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 export function trigger (target : any , key : string | symbol , type : string const depsMap = effectBucket.get (target)if (!depsMap) { return false }const effects = depsMap.get (key)const effectsToRun = new Set (effects)forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)if (type === TriggerType .ADD || type === TriggerType .DELETE ) {const iterateEffects = depsMap.get (ITERATE_KEY )forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)forEach ((effectFn ) => {const EffectFunctionOptions = effectFn.options as EffectOptions if (EffectFunctionOptions .scheduler ) {EffectFunctionOptions .scheduler (effectFn)else {effectFn ()
当值没有变化时,我们不应触发响应,例如p.foo 的初始值为 1,当为 p.foo
设置新的值时,如果值没有发生变化,则不需要触发响应。同时我们也要避免新值和旧值不全等时都不是NaN:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const refObj = new Proxy (data, {set (target, key, newVal, receiver ) {const oldVal = target[key]const type = Object .prototype hasOwnProperty .call (target, key) ? "SET" : "ADD" const res = Reflect .set (target, key, newVal, receiver)if (oldVal !== newVal && (oldVal === newVal || oldVal === newVal)) {trigger (target, key, type )return res
reactive接下来我们将上面的内容封装成一个reactive函数,接收一个对象作为参数,并返回为其创键的响应式数据。
我们设置一个iterateBucket,用来将上文提到的ITERATE_KEY和对应的对象联系起来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 const iterateBucket : WeakMap <any , any > = new WeakMap <any , any >()export function trigger (target : any , key : string | symbol , type : string if (type === TriggerType .ADD || type === TriggerType .DELETE ) {const ITERATE_KEY = iterateBucket.get (target)const iterateEffects = depsMap.get (ITERATE_KEY )forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)
当我们将一个响应式对象设置为另一个响应式对象的原型时,我们也会与副作用函数之间建立联系,当我们执行child.bar = 2类似的操作时,副作用会执行两次,产生不必要的更新。
1 2 3 4 5 6 7 const obj = {}const proto = {bar : 1 const parent = reactive (proto)const child = reactive (obj)Object .setPrototypeOf (child, parent)
对于get方法,如果对象自身不存在该属性,那么会获取对象的原型,并调用原型的[[Get]]方法得到最终结果。当读取child.bar属性值时,由于child
代理的对象 obj 自身没有 bar 属性,因此会获取对象 obj 的原型,也就是
parent
对象,所以最终得到的实际上是parent.bar的值。但是大家不要忘了,parent
本身也是响应式数据,因此在副作用函数中访问parent.bar的值时,会导致副作用函数被收集,从而也建立响应联系。所以我们能够得出一个结论,即child.bar和parent.bar都与副作用函数建立了响应联系。
对于set方法,如果设置的属性不存在于对象上,那么会取得其原型,并调用原型的[[Set]]方法,也就是
parent
的[[Set]]内部方法。换句话说,虽然我们操作的是child.bar,但这也会导致parent
代理对象的 set
拦截函数被执行。前面我们分析过,当读取child.bar的值时,副作用函数不仅会被child.bar收集,也会被parent.bar收集。所以当
parent 代理对象的 set
拦截函数执行时,就会触发副作用函数重新执行,这就是为什么修改child.bar的值会导致副作用函数重新执行两次。
我们先回顾一下receiver的定义: receiver
是本次读取/设置属性 所在的 this 对象。
解决方法就是屏蔽非当前操作对象的副作用函数。我们不难发现receiver就是target的代理对象,由于child中target中不存在bar属性,发生set操作时调用原型的[[Set]]方法触发parent的set拦截函数,由此可知parent的receiver就是代理对象child,而不再是parent的target的代理对象。因此我们可以根据receiver是不是target的代理对象来判断是否触发更新。
我们在get拦截函数添加:
1 2 3 4 5 6 7 get (target, key : string | symbol , receiver : any ) {if (key === "raw" ) {return targettrack (target, key)return Reflect .get (target, key, receiver)
当我们访问parent.raw时,会返回parent的原始对象。由此我们可以在set中进行receiver是不是target的代理对象的判断,如果是,则触发更新:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 set (target, key, newVal, receiver ) {const oldVal = target[key]const type = Object .prototype hasOwnProperty .call (target, key) ? "SET" : "ADD" const res = Reflect .set (target, key, newVal, receiver)if (receiver.raw === target) {if (oldVal !== newVal && (oldVal === oldVal || newVal === newVal)) {trigger (target, key, type )return res
深响应和浅响应 当我们代理对象中包含其他对象时,我们会丢失对这些对象的响应,所以我们现在实现的reactive是浅响应的。要解决这个问题,我们需要对
Reflect.get 返回的结果做一层包装:
1 2 3 4 5 6 7 8 9 10 11 12 get (target, key : string | symbol , receiver : any ) {if (key === "raw" ) {return targettrack (target, key)const res = Reflect .get (target, key, receiver)if (typeof res !== null && typeof res === "object" ) {return reactive (res)return res
然而并非所有情况我们都希望深响应,我们封装一个createReactive函数,传入第二个可选参数指定深浅响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 function createReactive (obj, isShallow = false ) {get (target, key : string | symbol , receiver : any ) {if (key === "raw" ) {return targettrack (target, key)const res = Reflect .get (target, key, receiver)if (isShallow) {return resif (typeof res !== null && typeof res === "object" ) {return reactive (res)return res
只读和浅只读 我们为createReactive添加第三个参数isReadonly:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 function createReactive (data : {[key: string | symbol ]: any }, isShallow = false , isReadonly = false any {const ITERATE_KEY = Symbol ()return new Proxy (data, {set (target, key, newVal, receiver ) {if (isReadonly) {console .warn (`property: ${key.toString()} is readonly` )return true deleteProperty (target : any , key : string | symbol if (isReadonly) {console .warn (`property: ${key.toString()} is readonly` )return true
如果一个数据是只读的,那就意味着任何方式都无法修改它。因此,没有必要为只读数据建立响应联系。出于这个原因,当在副作用函数中读取一个只读属性的值时,不需要调用
track 函数追踪,修改get拦截函数:
1 2 3 4 5 6 7 8 9 10 11 get (target, key : string | symbol , receiver : any ) {if (!isReadonly) {track (target, key)
同时为了实现深只读,让响应式对象内部的对象也设置为只读,修改get拦截函数:
1 2 3 4 5 6 7 8 9 10 get (target, key : string | symbol , receiver : any ) {if (typeof res !== null && typeof res === "object" ) {return isReadonly ? readonly (res) : reactive (res)
当isReadonly && !isShallow为true时,为深只读,反之为浅只读。
代理数组 读取操作:
通过索引访问数组元素值:arr[0]。
访问数组的长度:arr.length。
把数组作为对象,使用for...in循环遍历。
使用for...of迭代遍历数组。
数组的原型方法,如concat/join/every/some/find/findIndex/includes等,以及其他所有不改变原数组的原型方法。
设置操作:
通过索引修改数组元素值:arr[1] = 3。
修改数组长度:arr.length = 0。
数组的栈方法:push/pop/shift/unshift。
修改原数组的原型方法:splice/fill/sort等。
数组索引与length 通过数组的索引访问元素的值就会建立响应式联系,但通过索引设置数组的元素值与设置对象的属性值仍然存在根本上的不同。如果设置的索引值大于数组当前的长度,那么要更新数组的
length 属性。所以当通过索引设置元素值时,可能会隐式地修改 length
的属性值,因此在触发响应时,也应该触发与 length
属性相关联的副作用函数重新执行;当修改 length
属性值时,只有那些索引值大于或等于新的length属性值的元素才需要触发响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 set (target, key, newVal, receiver ) {const type = Array .isArray (target) ?Number (key) < target.length ? "SET" : "ADD" :Object .prototype hasOwnProperty .call (target, key) ? "SET" : "ADD" if (receiver.raw === target) {if (oldVal !== newVal && (oldVal === newVal || oldVal === newVal)) {trigger (target, key, type , newVal)if (type === TriggerType .ADD && Array .isArray (target)) {const lengthEffects = depsMap.get ("length" )forEach ((effectFn ) => {if (effectFn !== activeEffect) {add (effectFn)if (key === "length" && Array .isArray (target)) {forEach ((effects, key ) => {if (key.toString () >= newVal) {forEach (effectFn =>if (effectFn !== activeEffect) {add (effectFn)
遍历数组 使用for...in循环遍历数组与遍历常规对象并无差异,因此同样可以使用ownKeys拦截函数进行拦截。但我们需要注意的是会影响for...in循环遍历数组本质还是length:
添加新元素:arr[100] = 'bar'。
修改数组长度:arr.length = 0。
因此我们使用"length"来代替key:
1 2 3 4 5 ownKeys (target : any track (target, Array .isArray (target) ? 'length' : ITERATE_KEY )return Reflect .ownKeys (target)
接下来来看for ... of。该方法用于实现了迭代器的对象,数组内建了Symbol.iterator方法的实现。数组迭代器的执行会读取数组的
length
属性。如果迭代的是数组元素值,还会读取数组的索引。迭代数组时,只需要在副作用函数与数组的长度和索引之间建立响应联系 ,就能够实现响应式的for...of迭代。数组的
values
方法的返回值实际上就是数组内建的迭代器,在不增加任何代码的情况下,我们也能够让数组的迭代器方法正确地工作。
无论是使用for...of循环,还是调用values等方法,它们都会读取数组的Symbol.iterator属性。该属性是一个symbol值,为了避免发生意外的错误,以及性能上的考虑,我们不应该在副作用函数与Symbol.iterator这类symbol值之间建立响应联系,因此需要修改
get 拦截函数,如以下代码所示:
1 2 3 4 5 6 7 8 9 10 get (target, key : string | symbol , receiver : any ) {if (!isReadonly && typeof key !== "symbol" ) {track (target, key)
数组查找 1 2 3 4 const obj = {}const arr = reactive ([obj])console .log (arr.includes (arr[0 ]))
这个操作应该返回 true,但如果你尝试运行这段代码,会发现它返回了
false。问题出在include函数执行时会把当前代理对象当作内部this的值,在之前的实现我们知道通过代理对象来访问元素值时,如果值仍然是可以被代理的,那么得到的值就是新的代理对象而非原始对象,而即使参数
obj
是相同的,reactive创建的代理对象也都是不同的 ,因此arr内部创建的代理对象arr[0]与直接使用arr[0]并不相同。
解决方法是创建一个Map,用来建立原始对象和代理对象的联系:
1 2 3 4 5 6 7 8 9 function reactive (data ) {const existedProxy = reactiveMap.get (data)if (existedProxy) {return existedProxyconst proxy = createReactive (data)set (data, proxy)return proxy
当我们运行arr.includes(obj)时,由于我们直接拿着原始对象去找,肯定是找不到的,我们还需要重写includes方法。我们知道,arr.includes可以理解为读取代理对象arr的includes属性,这就会触发get拦截函数,在该函数内检查target是否是数组,如果是数组并且读取的键值存在于arrayInstrumentations上,则返回定义在arrayInstrumentations对象上相应的值。也就是说,当执行arr.includes时,实际执行的是定义在arrayInstrumentations上的includes函数,这样就实现了重写,indexOf和lastIndexof类似。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 const originMethod = Array .prototype includes const arrayInstrumentation = {includes : function (...args : any ): any {let res = originMethod.apply (this , args)if (res === false ) {apply (this .raw , args)return resget (target, key : string | symbol , receiver : any ) {if (Array .isArray (target) && arrayInstrumentation.hasOwnProperty (key)) {return Reflect .get (arrayInstrumentation, key, receiver)
隐式修改数组长度 主要指的是数组的栈方法,例如push/pop/shift/unshift。拿push来说:当调用数组的
push 方法向数组中添加元素时,既会读取数组的 length
属性值,也会设置数组的
length属性值 。这会导致两个独立的副作用函数互相影响。运行下面的代码会发生栈溢出:
1 2 3 4 5 6 7 8 9 const arr = reactive ([])watchEffect (() => {push (1 )watchEffect (() => {push (1 )
当第一个副作用函数执行完毕后会与length建立响应联系,当第二个函数执行时,也会建立联系。注意,push方法会设置length的值,执行第二个副作用函数时设置了length的值,响应系统会将其关联的所有副作用函数取出执行,其中包括第一个副作用函数。问题就出在这里。第一个副作用函数执行时又设置了length的值,又会导致第二个副作用函数的执行,就陷入了死循环,从而导致栈溢出。
问题的原因是 push 方法的调用会间接读取 length
属性。所以,只要我们“屏蔽”对 length
属性的读取,从而避免在它与副作用函数之间建立响应联系,其他的方法也类似。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const trackMethods = ["push" , "pop" , "shift" , "unshift" , "splice" ]forEach ((method : any {const originMethod = Array .prototype function (...args : any ): any {false let res = originMethod.apply (this , args)true return resif (!activeEffect || !shouldTrack) {return
代理Set和Map 我们不难发现 Map 和 Set
这两个数据类型的操作方法相似。它们之间最大的不同体现在,Set 类型使用
add(value) 方法添加元素,而 Map 类型使用 set(key, value)
方法设置键值对,并且 Map 类型可以使用 get(key)
方法读取相应的值,意味着我们可以用相同的处理办法来实现对它们的代理。
与普通对象不同,Set 和 Map
类型的数据有特定的属性和方法用来操作自身。
Set.prototype.size是一个访问器属性,我们需要修正访问器属性的
getter 函数执行时的 this 指向:
1 2 3 4 5 6 7 8 9 10 11 get (target, key : string | symbol , receiver : any ) {if (key === "size" ) {track (target, ITERATE_KEY ) return Reflect .get (target, key, target)
add & delete当删除元素时,size 是属性,是一个访问器属性,而 delete
是一个方法。当访问p.size时,访问器属性的getter函数会立即执行,此时我们可以通过修改
receiver 来改变 getter 函数的 this
的指向。而当访问p.delete时,delete方法并没有执行,真正使其执行的语句是p.delete(1)这样的函数调用 ,故此时target[key]是一个函数调用,只需要把
delete 方法与原始数据对象绑定即可:
1 2 3 4 5 6 7 8 9 get (target, key : string | symbol , receiver : any ) {const res = target[key].bind (target)if (typeof res !== null && typeof res === "object" ) {return isReadonly? readonly (res) : reactive (res)return res
有了思路以后,我们就可以实现Set类型数据的响应式方案了。对于add方法,Set工作方式为在副作用函数内访问了
p.size
属性;接着,调用p.add函数向集合中添加数据。由于这个行为会间接改变集合的size属性值,所以我们期望副作用函数会重新执行。为了实现这个目标,我们需要在访问size属性时调用
track
函数进行依赖追踪,然后在add方法执行时调用trigger函数触发响应。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 const mutableInstrumentation : {[index : string ]: any } = {add (key : string | symbol ): any {const target = this .raw const hadKey = target.has (key)const res = target.add (key)if (!hadKey) {trigger (target, key, "ADD" )return resdelete (key : string | symbol ): any {const target = this .raw const hadKey = target.has (key)const res = target.delete (key)if (!hadKey) {trigger (target, key, "ADD" )return resif (typeof key === "string" && setMethod.includes (key)) {return mutableInstrumentation[key]
这里需要注意的是,诸如console.log(p)一类的操作不会触发Set的getter,所以当你这么写时:
1 2 3 4 5 6 7 8 9 10 const p = reactive (new Set ([1 , 2 , 3 ]))setTimeout (() => {add (4 )1000 )watchEffect (() => {console .log (p)
不会触发任何响应,必须用别的可触发响应的数据来间接触发console.log(p)响应。
set & getMap数据类型拥有get和set这两个方法,当调用get方法读取数据时,需要调用track函数追踪依赖建立响应联系;当调用set方法设置数据时,需要调用trigger方法触发响应。
对于get,只需要注意在非浅响应的情况下,如果得到的数据仍然可以被代理,那么要调用
reactive(res)
将数据转换成响应式数据后返回。在浅响应模式下,就不需要这一步了。
1 2 3 4 5 6 7 8 9 10 get (key : any const target = this .raw const hadKey = target.has (key)track (target, key)if (hadKey) {const result = target.get (key)return typeof result === "object" ? reactive (result) : result
对于set,触发时需要区分SET和ADD操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 set (key : any , value : any const target = this .raw const hadKey = target.has (key)const oldVal = target.get (key)set (key, value)if (!hadKey) {trigger (target, key, "ADD" )else if (oldVal !== value && (oldVal === oldVal || value === value)) {trigger (target, key, "SET" )
但上面的代码会引发污染问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const m = new Map ()const p1 = reactive (m)const p2 = reactive (new Map ())set ('p2' , p2)watchEffect (() => {console .log (m.get ('p2' ).size )get ('p2' ).set ('foo' , 1 )
在副作用函数中,我们通过原始数据 m 来读取数据值,然后又通过原始数据 m
设置数据值,此时发现副作用函数重新执行了。原因是我们原封不动把value设置到了target上,意味着设置到原始对象上的也是响应式数据,我们把这种行为称为数据污染 。我们加上两行代码就解决了:
1 2 3 const rawVal = value.raw || valueset (key, rawValue)
forEach((value, key, m) => {})forEach的回调函数接收三个参数,分别是值、键以及原始 Map
对象。遍历操作只与键值对的数量有关,因此任何会修改 Map
对象键值对数量的操作都应该触发副作用函数重新执行,例如 delete 和 add
方法等。
所以当forEach函数被调用时,我们应该让副作用函数与ITERATE_KEY建立响应联系。但这里需要注意的是,我们不能直接用原生的forEach来实现,这样会导致传递给回调函数的参数是非响应式数据。其中第二个参数可以用来指定回调函数执行时的this值。
1 2 3 4 5 6 7 8 9 10 11 forEach (callback : Function , thisArg : any const wrap = (val : any typeof val === 'object' ? reactive (val) : valconst target = this .raw track (target, ITERATE_KEY , "SIZE" )forEach ((v : any , k : any {call (thisArg, wrap (v), wrap (k), this )
对于for...in只关心键值,而forEach即关心键又关心值。这意味着,当调用p.set('key', 2)修改值的时候,也应该触发副作用函数重新执行,即使它的操作类型是SET。因此,我们应该修改trigger函数的代码来弥补这个缺陷:
1 2 3 4 5 6 7 if (type === TriggerType .ADD || type === TriggerType .DELETE ||type === "SET" && Object .prototype toString .call (target) === "[Object Map]"
迭代器 集合类型有三个迭代器方法:entries, keys, values,由于
Map 或 Set
类型本身部署了Symbol.iterator方法,因此它们可以使用for...of进行迭代。我们也可以调用迭代器函数取得迭代器对象后,手动调用迭代器对象的next方法获取对应的值。实际上m[Symbol.iterator]与m.entries是等价的。
当我们使用for...of循环迭代一个代理对象时,内部会试图从代理对象p上读取p[Symbol.iterator]属性,这个操作会触发
get
拦截函数。使用for...of循环迭代集合时,如果迭代产生的值也是可以被代理的,那么也应该将其包装成响应式数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 function iterationMethod (this : any const target = this .raw const iterator = target[Symbol .iterator ]()console .log (target)const wrap = (val : any typeof val === 'object' && val !== null ? reactive (val) : valtrack (target, ITERATE_KEY , "SIZE" )if (target instanceof Map ) {return {next (const {value, done} = iterator.next ()return {value : value ? [wrap (value[0 ]), wrap (value[1 ])] : value,else if (target instanceof Set ) {return {next (const {value, done} = iterator.next ()return {value : value ? wrap (value) : value,
对于entries,切勿把可迭代协议与迭代器协议搞混。可迭代协议指的是一个对象实现了Symbol.iterator方法,而迭代器协议指的是一个对象实现了
next
方法。p.entries函数的返回值是一个对象,该对象带有next方法,但不具有Symbol.iterator方法。因此我们还需要返回一个[Symbol.iterate]:
1 2 3 4 5 6 7 8 9 10 11 12 13 return {next (const {value, done} = iterator.next ()return {value : value ? wrap (value) : value,Symbol .iterator ]() {return this
values方法的实现与entries方法类似,不同的是,当使用for...of迭代values时,得到的仅仅是Map数据的值,而非键值对
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 function valuesIterationMethod (this : any const target = this .raw let iterator : any = target.values ()const wrap = (val : any typeof val === 'object' && val !== null ? reactive (val) : valtrack (target, ITERATE_KEY , "SIZE" )return {next (const {value, done} = iterator.next ()return {value : wrap (value),Symbol .iterator ]() {return this
而keys得到的是Map数据的键,我们只需在iterationMethod增加判断即可。但这里需要注意的是,如果我们将Map的新值赋给原有的键,
不应该触发副作用函数响应。我们对 Map
类型的数据进行了特殊处理。前文提到,即使操作类型为SET,也会触发那些与ITERATE_KEY相关联的副作用函数重新执行,这对于values或entries等方法来说是必需的,但对于keys方法来说则没有必要,因为keys方法只关心Map类型数据的键的变化,而不关心值的变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 const MAP_KEY_ITERATE_KEY = Symbol ()function keysIterationMethod (this : any const target = this .raw let iterator : any = target.keys ()const wrap = (val : any typeof val === 'object' && val !== null ? reactive (val) : valtrack (target, MAP_KEY_ITERATE_KEY , "SIZE" )return {next (const {value, done} = iterator.next ()return {value : wrap (value),Symbol .iterator ]() {return this
由于我们在trigger中只针对ITERATE_KEY触发更新,更换标识后set方法就不会触发keys方法的更新了。
ref正如我们前面说的,由于Proxy实现的reactive只能劫持对象,无法代理原始值,因此想要将原始值变成响应式数据,就必须对其做一层包裹。我们可以封装一个函数,将包裹对象的创建工作都封装到该函数中。同时,我们还需要区分一个对象到底是原始值的包裹对象,还是一个非原始值的响应式数据:
1 2 const refVal1 = ref (1 )const refVal2 = reactive ({ value : 1 })
方法也很简单,使用Object.defineProperty为原始值的包裹对象添加标记即可:
1 2 3 4 5 6 7 8 9 10 11 function (data ) {const wrapper = {value : dataObject .defineProperty (wrapper, '_is_Ref_' , {value : true return reactive (wrapper)
响应丢失 ref
除了能够用于原始值的响应式方案之外,还能用来解决响应丢失问题。在进行例如解构操作时,容易是返回了一个普通对象,它不具有任何响应式能力。把一个普通对象暴露到模板中使用,是不会在渲染函数与响应式数据之间建立响应联系的。换句话说,我们需要实现在副作用函数内,即使通过普通对象来访问属性值,也能够建立响应联系。
在之前的实现中,我们使用get等方法来拦截数据的读取操作。我们可以用类似的想法来实现通过普通对象来访问属性值的响应联系建立。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 function toRefs (obj : {[index: string | symbol ]: any }, key : any Ref <any > {const wrapper = {get value () {return obj[key]set value (val ) {Object .defineProperty (wrapper, '_is_Ref_' , {value : true return wrapper
自动脱ref 由于toRefs会把响应式数据的第一层属性值转换为
ref,因此必须通过 value 属性访问值。所谓自动脱
ref,指的是属性的访问行为,即如果读取的属性是一个ref,则直接将该ref对应的value属性值返回,要实现此功能,需要使用Proxy为newObj创建一个代理对象,通过代理来实现最终目标,这时就用到了上文中介绍的
ref 标识,即_is_Ref_属性。
实际上,我们在编写 Vue.js
组件时,组件中的setup函数所返回的数据会传递给proxyRefs函数进行处理,这也是为什么我们可以在模板直接访问一个
ref
的值,而无须通过value属性来访问。既然读取属性的值有自动脱
ref 的能力,对应地,设置属性的值也应该有自动为 ref 设置值的能力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 export function proxyRef (target : any any {return new Proxy (target, {get (target, key, receiver ) {const value = Reflect .get (target, key, receiver)return value._is_Ref_ ? value.value : valueset (target, key, newVal, receiver ) {const value = target[key]if (value._is_Ref_ ) {value = newValreturn true return Reflect .set (target, key, newVal, receiver)
在 Vue.js
中,reactive函数也有自动脱ref的能力。
总结 在本篇文章,我们先分析了Vue的MVVM的整体架构,主要实现了最基本的响应式系统。实现一个响应式系统最重要的一点就是理解副作用。副作用函数指的是会产生副作用的函数。当一个函数执行时,会直接或间接影响其他函数的执行,这时候我们就称这个函数产生了副作用。副作用很容易产生,例如我们在文章中经常提到的document.body.innerText = refObj.bar,他的设置会改变其他代码对文本内容的设置;再比如修改全局变量等等。我们称refObj.bar为副作用函数的依赖,副作用函数会因为依赖的变化而产生副作用。
那么响应式是什么?Vue
最标志性的功能就是其低侵入性的响应式系统。响应式就是当数据变化时,视图也会随机自动更新。这里的更新就是重新触发数据(依赖)关联的副作用函数。那我们的响应式系统就要做到能够创建响应,并收集响应式数据相关联的副作用函数,当响应式数据发生改变时,重新触发这些副作用函数。
我们首先需要拦截对响应式数据的读写操作。由于Proxy的易用性,在Vue3中采用Proxy代替了Object.defineProperty来实现数据劫持。我们使用get方法拦截数据的读取操作,用set方法拦截数据的设置操作。这个思路会贯穿整个响应式系统的实现。
在使用get方法拦截数据的读取操作时,我们需要追踪该数据,并收集其关联的副作用函数,将这些函数存入一个储存副作用函数的桶effectBucket中(track),并在使用set方法拦截数据设置操作时根据需要重新执行他们(trigger)。这里我们使用了activeEffect来作为中间变量来操作副作用函数的存储。
我们知道代理对象、字段名(对象键值)与副作用函数之间存在着树状关系,因此他们对应的数据结构也是树状的。为了防止内存溢出,我们使用weakMap来作为存储所有副作用函数的桶。weakMap在代理对象没有任何引用的情况下会自动触发垃圾回收机制,从而避免了内存溢出。EffectBucket储存着字段名(对象键值)与副作用函数依赖集合的键值对,当我们在track函数中进行副作用函数的存储时,根据树状结构依次存储相关的信息。
而对于set方法我们使用trigger函数触发更新。我们只需要根据字段名在EffectBucket中找到对应的副作用函数依赖集合,并重新运行里面存放的副作用函数就可以了。
这里我们可能会遇到一些不必要的更新。当某一变量发生变化时,代码执行的分支可能也会随之变化,称为分支切换。当发生分支变换时,我们不一定需要执行原有的副作用函数,因此我们在每次将副作用函数添加到依赖集合时,先清空依赖集合中原有的副作用函数,再通过track将当前代码执行分支所需的副作用函数添加到EffectBucket中。
在副作用函数中可能会嵌套另一个副作用函数。如果存在effect嵌套,我们目前的系统全局activeEffect永远是初始化时最后执行的那个副作用函数。为了解决这个问题,我们需要一个副作用函数栈effectStack,副作用函数执行时压栈,执行完毕后退栈,并始终让activeEffect指向栈顶。
当我们遇到形如obj.foo++这类调用自身的副作用函数时,需要避免无限递归循环。在这个副作用函数中,读取obj.foo会触发track,而将更新完后的值赋给本身又会触发trigger,从桶中取出副作用函数重新执行,而我们当前就正在处理这个副作用函数,这样就导致了无限递归调用自身。所以我们需要在trigger中添加护卫条件,当当前执行的副作用函数与触发的副作用函数相同时,则不触发执行。
可调度是响应式系统非常重要的特性。当trigger触发副作用函数执行时,应有能力决定副作用函数执行时机、次序以及方式,我们为副作用函数增加了一个选项参数调度器scheduler,如果该属性存在,则按照scheduler函数来执行副作用函数。我们可以使用调度器来实现多次修改响应式数据只触发一次更新(使用Promise创建微序列)。
计算属性computed就是通过调度器实现的。首先我们先为副作用函数选项添加懒加载lazy,用于不希望函数立即执行,而在需要的场景执行的情况。接下来我们需要修改用来监听副作用的watchEffect:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 function watchEffect (fn : EffectFunction , options : EffectOptions = {}EffectFunction {const effectFn : EffectFunction = () => {cleanup (effectFn)push (activeEffect)const res = fn ()pop ()length - 1 ]return resoptions = optionsdeps = []if (!options.lazy ) {effectFn ()return effectFn
这样处理后,不难看出传递给effect的函数fn才是真正的副作用函数,effectFn的返回值就是副作用函数的执行结果。仅当lazy属性为false时才执行该函数,返回effectFn,用于在需要的时候调用。我们把传递给watchEffect的函数看作一个getter,那么我们在手动执行副作用函数时,就可以拿到返回值
对于计算属性,我们还需要缓存计算结果,而不是读取时才进行计算。我们实现一个调度器,引入dirty实现脏读,进行计算后设置为false,当其为true时才执行副作用函数重新计算。当在watchEffect里读取computed的计算值时会发生嵌套,我们需要get方法中调用track函数来收集computed内层的响应式数据;当计算属性依赖的响应式数据发生变化时,通过调度器手动调用trigger函数。
watch
本质是观测一个响应式数据,当数据发生变化时通知并执行相应的回调函数。watch的实现本质就是利用了watchEffect以及scheduler选项,当响应式数据发生变化时,触发scheduler调度函数执行,相当于一个回调函数。我们需要一个traverse函数进行递归读取操作,watch函数允许观测响应式数据和getter函数,同时能通过lazy在回调函数中获取旧值和新值。
当然如果我们在执行异步编程时,可能会发生竞态问题,于是我们需要引入onInvalidate来注册一个回调,当在watch内部检测到变更时,在副作用函数重新执行之前会先调用我们通过onInvalidate注册的过期回调。这时我们可以设置一个过期标识expired,如果为真,则不将此次获得的结果赋给最终结果。
实现了响应式基础,接下来我们来具体实现响应式系统。在平时使用Vue的时候我们就经常用到reactive和ref。reactive只能用于创建对象的响应式,无法创建原始值的响应式,这部分就由ref来实现。
这里说说Reflect。Reflect
是一个内建对象,可简化 Proxy 的创建。对于任意
Proxy 捕捉器,都有一个带有相同参数的 Reflect
调用。我们可以使用它们将调用转发给目标对象,也可以将操作转发给原始对象。Reflect.get函数还能接收第三个参数,即指定接收者receiver,你可以把它理解为函数调用过程中的this。这里我们用receiver在大部分情况下指定this为代理对象,以避免指向原始对象丢失响应。
接下来就是对对象的各种方法进行拦截了。对于一些只有一个target参数的操作方法,我们使用ITERATE_KEY来作为effectBucket的键值。触发时我们只需要将于ITERATE_KEY相关联的副作用函数也取出来执行即可。
无论是添加或删除新属性,还是修改已有的属性值,其基本语义都是[[Set]],我们都是通过
set
拦截函数来实现拦截的,设置属性操作发生时,就需要我们在set拦截函数内能够区分操作的类型,并在trigger中通过type区分当前操作类型,并且只有当操作类型type为
‘ADD’ 和 ‘DELETE’
时,才会触发与ITERATE_KEY相关联的副作用函数重新执行。将上述拦截方法封装,就是reactive函数了。对于异常对象的处理思路也类似,但我们需要创建一个中间对象来拦截一些特殊的方法,比如[Symbol.iterate]。这里我们需要注意处理数组的push方法时需要屏蔽对length属性的读取,否则会引起死循环。
接下来ref的实现就简单了。我们只需要将非对象类型数据用对象包裹,并用Object.defineProperty添加响应标识_is_Ref_,并根据响应标识_is_Ref_来自动脱ref实现在模板等使用环境中直接读取数据而不用通过value字段读取。
最后在这里放个源码,更新中
CainHappyfish/vue-mvvm-domo
(github.com)
参考
Foreverddb/DdBind:
DdBind
深入响应式系统
| Vue.js (vuejs.org)
Mvvm框架复写
(yuque.com)
Vue.js设计与实现
(ituring.com.cn)
手写一套完整的基于Vue的MVVM原理
Vue3的Proxy响应式原理
渲染机制
| Vue.js (vuejs.org)
vuejs/core: 🖖 Vue.js is a
progressive, incrementally-adoptable JavaScript framework for building
UI on the web. (github.com)